Recently, I needed to group about 1000 terms into a number of categories.
Doing it manually was far too painful, so I turned to machine learning as it can be so good for these kinds of tasks.
Specifically, I used the torch and transformers library from Hugging Face. Their pipeline function makes setting up a model and performing various tasks really simple. In this case, I used the zero-shot-classification pipeline, which lets us classify text into categories without needing a pre-trained model specific to our labels. In other words, someone else has already done the heavy lifting of training a model perfect for this use case.
Given how much of a time-saving this was, I thought I’d record the process in case it’s useful for anyone else. This will be a simplification, but it should be simple enough to read between the lines.
Zero-Shot Classification Explained
Unlike traditional machine learning models that need to be trained on specific pre-defined categories, zero-shot classification can categorise text into labels it hasn’t seen before (i.e. data it wasn’t trained on). It’s similar to having a grad student organise your stuff without needing to give them examples first, they just understand how the info needs to be organised based on the categories you tell them. The below image probably speaks a thousand words:
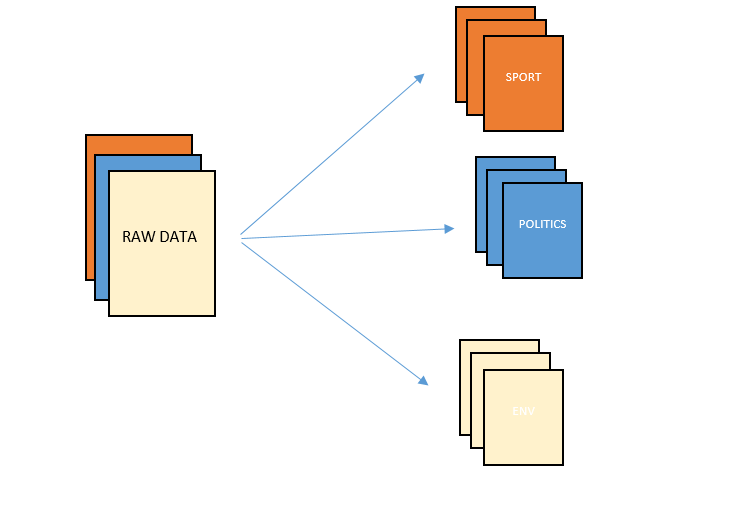
This is really useful when you need to sort data into custom categories without having a huge dataset (or the time) to train a new model.
This is all possible because of the ‘Transformers’ architecture – these are just models that understand and generate human language by understanding the meaning, context and relationship between words. We’ll be using the Hugging Face library, which gives us easy access to these pre-trained models.
The Goal
Categorise a list of about 1000 terms into predefined categories using zero-shot classification to save me having to do it manually.
Setting Up the Code
First, import the necessary libraries and set up our environment:
import torch
from transformers import pipeline
import pandas as pd
import csv
import ioSpecify that you want to use the first GPU available in your PC rather than your CPU. GPUs can process many more tasks in parallel than CPUs which speeds things up massively, so there’s no reason to not do this.
device = 0 # Use the first GPUNext, I loaded the CSV file containing the keywords I wanted to categorise. I used Python’s built-in csv module to read the file and then wrote it into an in-memory buffer using io.StringIO. This just ensures compatibility when loading the data into a pandas DataFrame, which makes data manipulation much easier.
with open("\\text_to_cluster.csv", "r", encoding="utf-8") as file:
reader = csv.reader(file)
csv_file = list(reader)
csv_buffer = io.StringIO()
writer = csv.writer(csv_buffer)
writer.writerows(csv_file)
csv_buffer.seek(0) # Move the cursor back to the beginning of the buffer
df = pd.read_csv(csv_buffer)I then defined a batch size for processing the keywords. Processing in batches helps manage memory usage and ensures the model runs smoothly. The classifier is set up with the facebook/bart-large-mnli model, which is a great model for a lot of different natural language processing tasks.
batch_size = 16 # see how big you can make this number before OOM
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=device)I listed out the categories I wanted to classify my keywords into.
labels = ['research methods', 'academic writing', 'statistics and data analysis', 'general science', 'psychology and social science',
'marketing and business', 'history']Finally, I iterated over the keywords in batches, feeding them into the classifier. The results were printed out, showing each keyword and its corresponding category. This simple loop does all the heavy lifting, classifying each term accurately and efficiently.
sequences = df['Keyword'].to_list()
for i in range(0, len(sequences), batch_size):
result = classifier(sequences[i:i+batch_size], labels, multi_label=False)
for i in result:
sequence = i['sequence'].rstrip('\n')
match = i['labels'][0]
print(f'{sequence} | {match}')And that’s it! In just a few lines of code, I managed to categorise over 1000 terms in a few minutes instead of a few days!
